Il y a quelques jours, sur Nexen, je tombais sur un article portant sur la micro-optimisation, et peu de temps après, sur une “réponse” de Zenprog.
Comme je trouve le sujet intéressant et que j’ai un avis complémentaire, bien que différent, je me permet dont d’écrire cet article pour l’exposer.
Différence entre temps d’exécution et temps de rendu
Pour ma part, je trouve la micro-optimisation assez peu intéressante dans le sens où elle est micro. Cette optimisation se base en tout et pour tout sur le temps d’exécution brut d’un script PHP, en se demandant si je peux gagner 10% en remplaçant tout mes echo par des print, ou alors en utilisant des “ au lieu de ‘.
Sauf que, dans la vie d’une application web, ce temps n’est rien. Pour enfoncer une porte ouverte, le fonctionnement du web se décompose en plusieurs phases :
- Envoi d’une requête : interroger les serveurs DNS, trouver le serveur et ouvrir une connexion avec lui.
- Génération de la réponse : le temps d’exécution
- Téléchargement du résultat : le temps que le HTML généré par le PHP reviennent sur le client
- Interprétation du résultat : le temps que le navigateur interprète le HTML, découvre les ressources nécessaire au rendu
- Chargement des ressources annexes (assets) : pour chaque ressource, on repart du début (requête, réponse, téléchargement et interprétation)
Le temps de rendu est l’ensemble des temps nécessaires pour réaliser toutes ces phases.
Prenons l’exemple, au hasard, d’un moteur de recherche bien connu, et analysons le chargement de la page d’accueil :
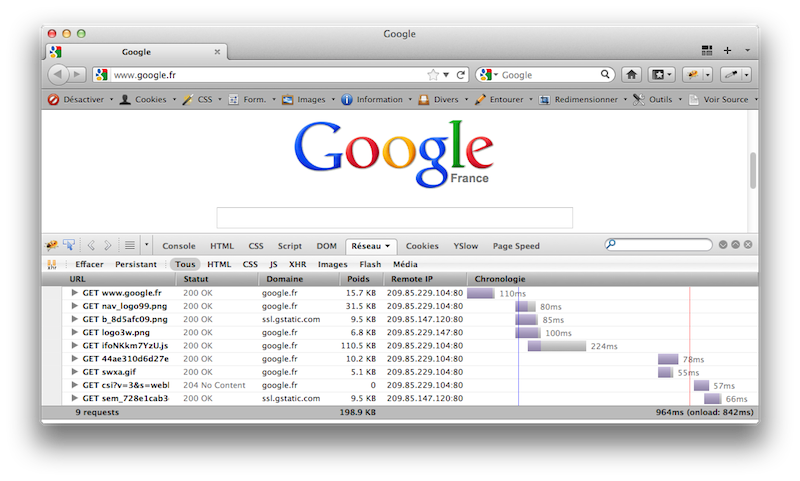
Voici ce que l’on peut apprendre de cette analyse :
- le temps complet de chargement de la page est de 964ms
- la requête initiale (requête, génération, téléchargement du résultat) prend 110ms (95ms de génération du résultat)
Il est donc clair que le temps de rendu (le temps nécessaire pour que l’utilisateur puisse utiliser la page) est 9 fois plus important que le temps d’exécution du script sur le serveur. Du coup, gagner 10% sur le temps d’exécution ne fait gagner que 1% sur le temps de rendu.
Et je parle ici de la page d’accueil de Google, qui optimise beaucoup ses chargements, mais pour d’autres sites, moins optimisé, c’est encore pire dès que le nombre de CSS, de JS ou d’images croît.
Optimisez vos chargements
Pour agir de façon drastiquement efficace sur votre temps de rendu, tant que le temps d’exécution est inférieur à 75% du temps de rendu, c’est du côté du chargement qu’il faut chercher.
Pour agir sur le chargement, j’utilise 2 outils : Page Speed et Yslow. Ces outils se basent sur une liste d’optimisations de chargement de pages web.
Je vous conseille de ne pas chercher à atteindre la perfection sur tout les points, mais c’est une bonne base de travail. Je vous conseille également de travailler avec les 2 outils en parallèle, car ils ne sont pas toujours d’accord, et cela permet de pondérer les conseils de chacun.
Micro-optimisation vs. macro-optimisation
Sur ce point, je suis totalement d’accord avec ZenProg : commencer par ce qui apporte réellement un gain de performance à vos sites !
Par expérience, je sais que lorsqu’un script PHP est lent, il faut commencer par traquer les causes suivantes :
- Requêtes non optimisées
- Schéma de base de données non optimisé
- Requêtes dans des boucles
- Boucles non optimisées
Requêtes non optimisées
Faire un EXPLAIN PLAN est un minimum vital pour des requêtes un minimum complexe. Dans de (trop) nombreux cas, 80% du temps d’exécution du script est l’oeuvre d’une requête non optimisée qui bloque le PHP
Schéma de base de données non optimisé
Comme le dit ZenProg, un index bien pensé (un index sur le(s) champ(s) sur lequel/lesquels se base les requêtes les plus fréquentes) permet de gagner beaucoup de temps, pour la même raison que pour le point précédent.
Requêtes dans une boucle
L’une des plus grosses fautes de développement, selon moi, c’est de ne pas contrôler les requêtes générées par son code source. Il est très facile de se retrouver dans un cas de figure où une requête est exécutée dans une boucle, surtout avec les frameworks MVC.
Contrôler le nombre de requêtes générées, et travailler sur des données de test réalistes (des dizaines d’enregistrement minimum) permettent donc de se rendre compte quand le nombre de requêtes d’une page semble trop important pour le travail réalisé, et donc se rendre compte qu’on a des requêtes inutiles.
Boucles non optimisées
Je vois trop souvent des algos qui, suite à plusieurs évolutions, se retrouvent avec plusieurs parcours d’un même tableau.
Au final, c’est du temps perdu lors des milliers/millions d’exécution de l’algo, juste parce le développeur n’a pas voulu “perdre” quelques minutes à prendre du recul sur son algo.
La lisibilité du code
Je sais que je sors un peu du sujet, mais je trouve qu’on y perd plus lorsque la micro-optimisation d’un code source rend sa lecture difficile
L’optimisation hors script
Je ne pouvais pas finir cet article portant sur l’optimisation sans parler de l’optimisation que j’appelle “hors site”.
J’entends par là qu’il y a des optimisations qui sont applicables sans se pencher sur un script, mais qui améliorent drastiquement son temps d’exécution :
- Mettre en place un cache d’Opcode (APC, …)
- Mettre en place un cache de rendu
Conclusion
Pour moi, bencher si print est plus efficace que echo, c’est de la masturbation intellectuelle pour la plupart des développeurs web que nous sommes.
Après la démonstration que je viens de vous faire, je pense que le jour où vous en serez réduis à remplacer vos print par des echo dans votre code source pour l’optimiser, c’est que vous aurez des besoins en performance très particulier, et que vous aurez déjà éculé les optimisations que je vous ai listées.